
How to Scrape Any Website Using Bright Data MCP Server and AI Agents

TL;DR
Built a real-time sneaker scraper using Bright Data’s MCP Server, LangChain, Claude, and FastAPI. This tool bypasses scraping blocks and extracts live Nike product data like price, availability, and links. Code is open-source.
I came across the Bright Data MCP (model context protocol) server from Noah Kalson and decided to try my hands on this incredible tool.
Bright Data MCP server is a unified, AI-ready access layer that provides seamless, scalable, and unblockable access to any public websites enabling LLMs, agents and apps to access, discover and extract web data in real-time.
The common problem I found worthy of solving was to scrape a public website like Nike.com particularly sneakers for men and have it readily available for users to view showcasing details like the product item, price, availability, and product link.
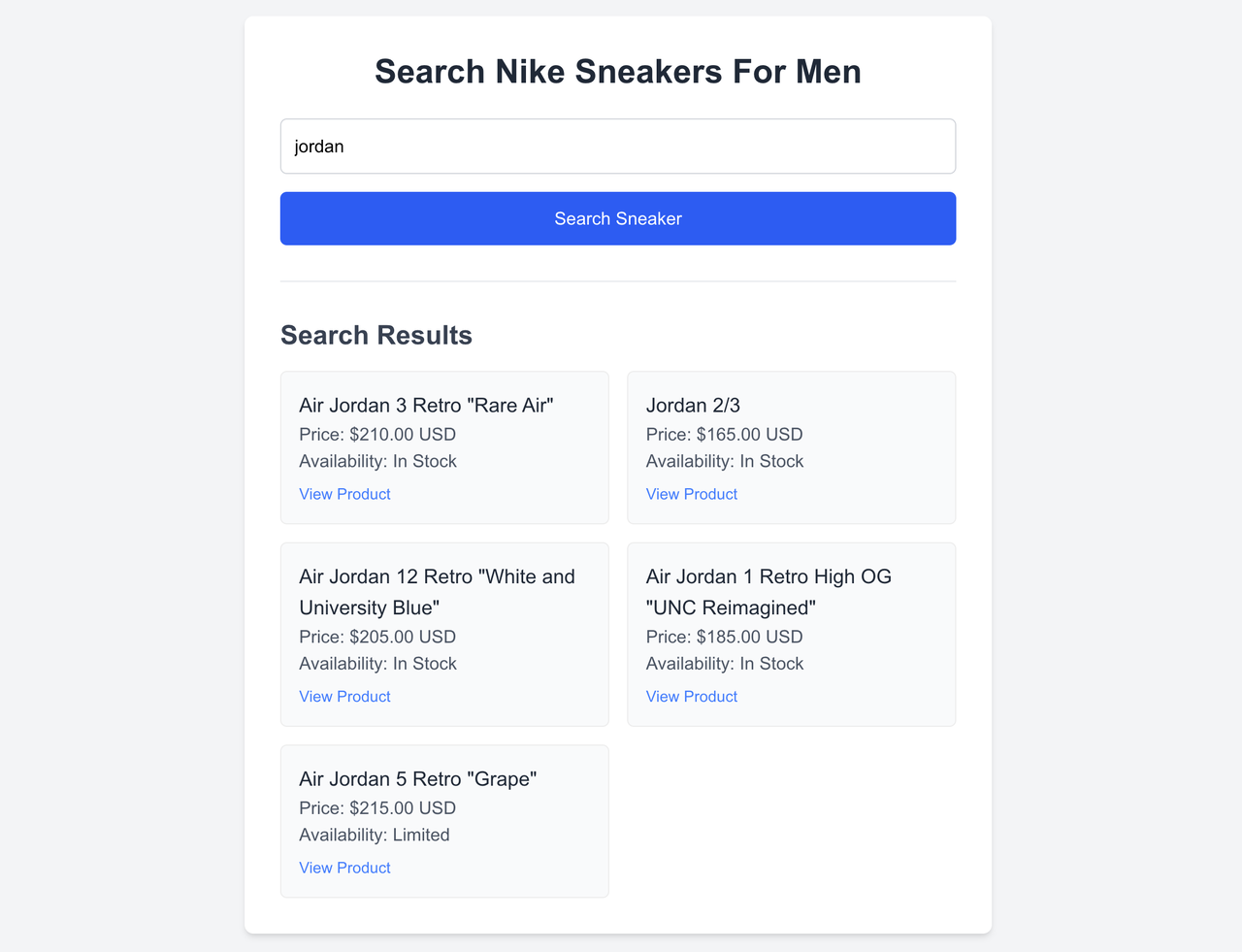
So I built this all in one tool that allows for the extraction of its data without any restriction because with Bright Data MCP, your applications can effortlessly retrieve both static and dynamic content from across the web, eliminating the need to build or maintain complex data scraping and unlocking infrastructure.
For technologies used in the project, I used:
-
LangChain: allows for the connection to multiple servers or LLM providers at the same time.
-
LangGraph: connects to all the request points or nodes together.
-
next.js: A React framework for building scalable and user friendly UI interface
-
Python: for the backend using FastAPI.
-
Claude (Anthropic API): to orchestrate multiple operation.
Here’s a walkthrough of the final product in this demo.
The code is public for viewing, check this repo.
Let me know what you think by giving this app a try and searching for your favorite Nike sneaker.
